The power of quality queries (and why they must stay the same)
A GEO audit is only as honest as the questions behind it. How Tripcite writes conversational, real-buyer queries in English, Spanish or both, lets you edit them, and re-runs the exact same set every month so the before and after is real.
A GEO audit is only as honest as the questions behind it. You can measure your share of model across every AI engine on earth, but if the queries are wrong, the number is noise. Query quality is the part nobody talks about, and the part that decides whether your audit reflects reality or a fantasy.
Keywords are not questions
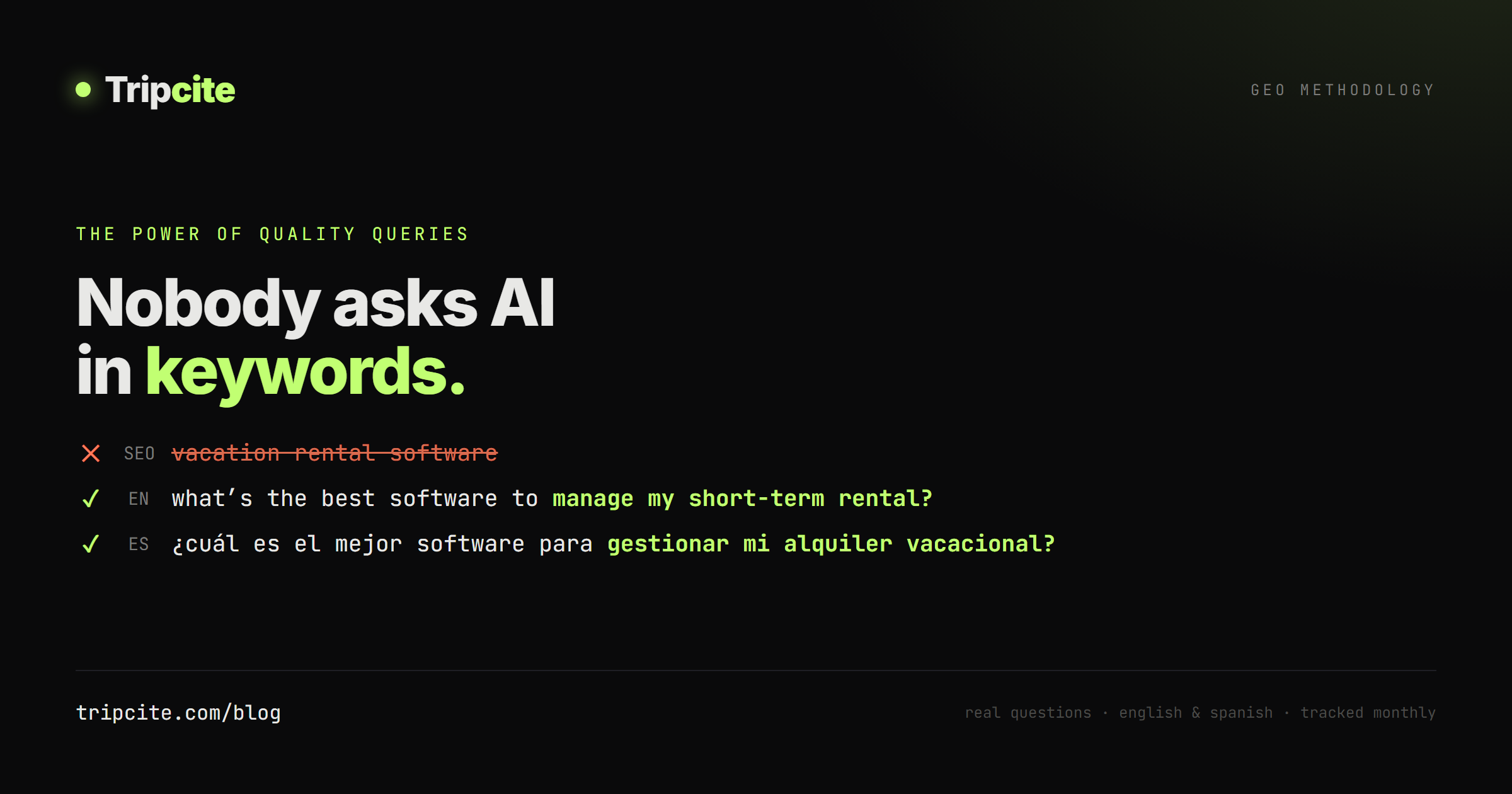
Nobody types “vacation rental software” into ChatGPT. They type a full sentence, the way they would ask a knowledgeable friend. A keyword measures nothing about how AI actually answers buyers. A real question measures everything.
✗ vacation rental software
✓ what is the best software to manage my short-term rental business?
The second one is a quality query: conversational, specific, and shaped by real intent. It maps to a moment in the buyer journey, and it is exactly the kind of prompt an AI will answer with a recommendation. Measure that, and you learn whether the AI names you when it matters. Measure the keyword, and you learn nothing.
Your buyers’ language is the query’s language
AI engines answer in the language you ask. So a Spanish business measured with English queries is measuring the wrong market entirely. The questions have to be written the way your buyers really talk, in their language.
🇬🇧 which company can organize a football tour in Spain for my U16 club?
🇪🇸 ¿qué empresa organiza viajes de fútbol en España para mi club sub-16?
Tripcite generates your queries in English, Spanish, or both. It reads your real site and writes them in the language your customers search in. And when you serve both markets, the “both” mode runs a balanced bilingual set and reports your share of model per language, so you see precisely where you win and where you are invisible. A brand that dominates in Spanish and disappears in English needs to know that, and a single combined number would hide it.
Grounded in your site, then edited by you
Quality does not mean generic. Tripcite reads what you actually sell and drafts queries across the whole buyer journey, then hands them to you to refine:
- Transactional queries (ready to buy): “who organizes group sports tours in Spain?”
- Informational queries (researching): “how much does a 7-day school trip to Spain cost?”
- Reputational queries (trust checks): “is [your brand] any good?”
You add the questions your sales team actually hears, cut the ones that miss, and reword anything that does not sound like your customer. You own the final set. That edit is what turns a decent draft into a query bank that truly represents your market.
The same queries, every month. That is the whole point.
A share-of-model number means little on its own. It means everything in a trend. If you are named in 14% of AI answers today and 28% next month, that is proof your GEO work is paying off, the before and after that proves the tool works. But it is only real if you asked the exact same questions, on the same engines. Change the queries and you do not have a before and after, you have two unrelated snapshots.
So Tripcite locks your approved query set and, on the monthly re-audit, runs the identical questions through the identical engines. That consistency is what makes the comparison honest. If you add a new query later, it is flagged and kept out of the trend until it has its own history, so a changed set never quietly inflates or deflates your progress.
One honest caveat that keeps the tracking real: the number only moves if you actually ship the fixes from your action plan. If you change nothing, your share of model stays flat, and that is useful information too. Same questions, same engines, month after month: that is how you turn a one-off audit into a track record you can show your boss or your board.
Why this is the moat
Anyone can hit an API and count brand mentions. The hard, valuable part is asking the right questions, in the right language, consistently over time. Quality queries are the difference between a vanity metric and a number that maps to your pipeline, and between a screenshot and a trend you can manage.
Want to see your real questions? Run a free Tripcite audit in English, Spanish or both, edit the queries to fit your market, and re-run them next month to watch the line move.
What is your share of model?
See how often ChatGPT, Perplexity, Gemini and Claude cite your brand versus your competitors. Get a baseline audit.